
This "Hands-On Machine Learning with Scikit-Learn & TensorFlow" is the very first book I've read about ML. I know reading such a book at this time point is a bit out of my business, but maybe it won't be a waste of time if just do this in free time and keep making notes (in English, this is very important).
The first chapter mainly contains basic knowledge of ML. Here the classification of ML model can be important because it decides how to build models for a specified problem.
What Does ML Do?
Well, I do think always determining a definition with broad and narrow definitions is pretty complex. And I think to answer this question these two graphs could be enough:
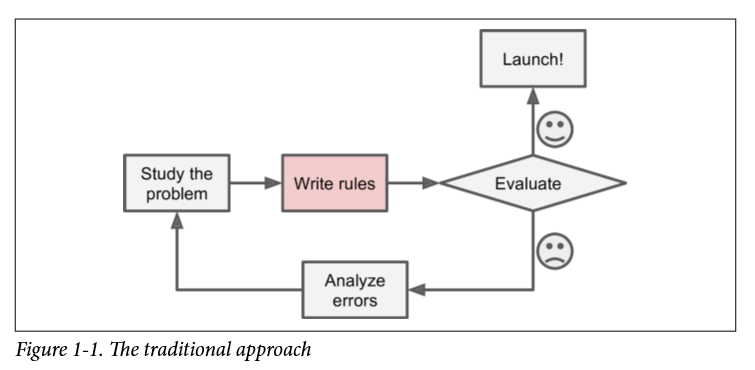
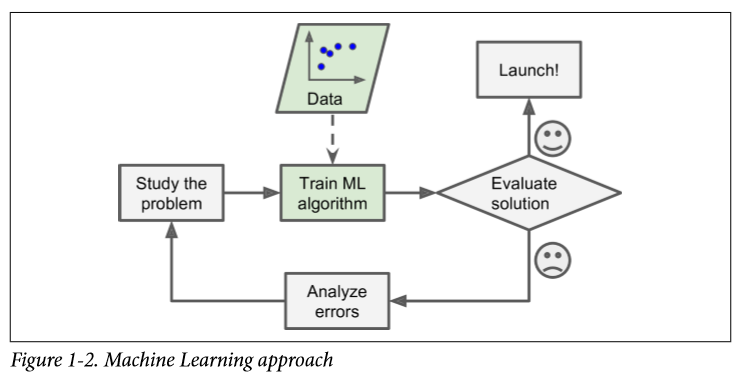
So ML is a script that has the ability to self-strengthen.
NOTE
To summarize, Machine Learning is great for:
- Problems for which existing solutions require a lot of hand-tuning or long lists of rules: one Machine Learning algorithm can often simplify code and perform better.
- Complex problems for which there is no good solution at all using a traditional approach: the best Machine Learning techniques can find a solution.
- Fluctuating environments: a Machine Learning system can adapt to new data.
- Getting insights about complex problems and large amounts of data.
Types of ML Systems
NOTE
There are so many different types of Machine Learning systems that it is useful to classify them in broad categories based on:
- Whether or not they are trained with human supervision (supervised, unsupervised, semisupervised, and Reinforcement Learning)
- Whether or not they can learn incrementally on the fly (online versus batch learning)
- Whether they work by simply comparing new data points to known data points, or instead detect patterns in the training data and build a predictive model, much like scientists do (instance-based versus model-based learning)
Supervised/Unsupervised Learning
Supervised learning
Normally, you train the system with a labeled dataset.
The first kind of supervised learning task is classification, like a spam filter: it is trained with many example emails along with their class (spam or ham), and it must learn how to classify new emails.
And the second kind of supervised learning task is to predict a target numeric value, such as the price of a car, given a set of features (mileage, age, brand, etc.) called predictors. This sort of task is called regression. To train the system, you need to give it many examples of cars, including both their predictors and their labels (i.e., their prices). So you see, this kind of ML is very important for us economists.
NOTE
In Machine Learning an attribute is a data type (e.g., “Mileage”), while a feature has several meanings depending on the context, but generally means an attribute plus its value (e.g., “Mileage = 15,000”). Many people use the words attribute and feature interchangeably, though.
Here are some of the most important supervised learning algorithms:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural networks2
Unsupervised learning*
In unsupervised learning, the training data is unlabeled. Currently not understand this segment well, further study is needed.
NOTE
Here are some of the most important unsupervised learning algorithms:
- Clustering (聚类)
- k-Means
- Hierarchical Cluster Analysis (HCA)
- Expectation Maximization
- Visualization and dimensionality reduction
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally-Linear Embedding (LLE)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- Association rule learning
- Apriori
- Eclat
- Semisupervised learning
- Anomaly detection (eg. detecting unusual payment)
Semisupervised learning
Some algorithms can deal with partially labeled training data, usually a lot of unlabeled data and a little bit of labeled data. A typical example is Google Photos.
Reinforcement Learning*
Learing by rewards and penalties. Further study needed. AlphaGo is a good example.
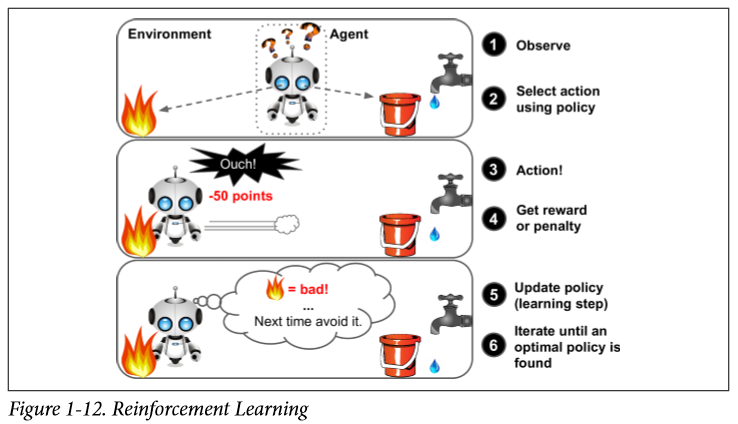
Batch and Online Learning
Whether or not the system can learn incrementally from a stream of incoming data.
Batch learning
Training off line and launching into production without learning any more. Every time to add new data to example dataset, the system need to scratch on the full dataset again, not just the new data, but also the old data.
It's time token and resources occupation, so we need online learning.
Online learning
Training the system incrementally by feeding it data instances sequentially, either individually or by small groups called mini-batches.
It can also be used to train systems on huge datasets that cannot fit in one machine’s main memory.
NOTE
This whole process is usually done offline (i.e., not on the live system), so online learning can be a confusing name. Think of it as incremental learning.
In online learning, you should be very cautious about bad data.
Instance-Based Versus Model-Based Learning
Categorizing Machine Learning systems is by how they generalize (一般化?).
Most Machine Learning tasks are about making predictions. This means that given a number of training examples, the system needs to be able to generalize to examples it has never seen before. Having a good performance measure on the training data is good, but insufficient; the true goal is to perform well on new instances.
In one words, I think it means your algorithm could generally used to another datasets, not only to specified dataset. Actually this is why we do it with codes instead of Excel aha?
Instance-based learning*
Not understand well, only beacuse of my poor English? 😦
In my currently understanding it means learning not only by the same label, but also the similar label.
Model-based learning
This is pretty like what we do on Excel—try to regress with different functions. In this case, the functions are models, such like linear models and so on.
This is the first example code making linear regression with Scikit-Learn:
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn
# Load the data
oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# Prepare the data
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# Visualize the data
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# Select a linear model
lin_reg_model = sklearn.linear_model.LinearRegression()
# Train the model
lin_reg_model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[22587]] # Cyprus' GDP per capita
print(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]
Main Challenges of Machine Learning
Bad algorithm vs. bad data.
Insufficient Quantity of Training Data
Quantity is important. There's also an interesting research find that a huge number of data could make up the shortages on algorithm. If you have a lot of data money, you can do whatever you like. XD
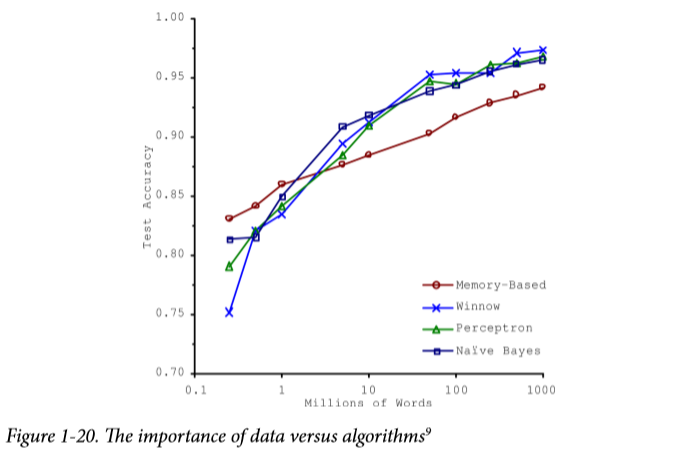
Nonrepresentative Training Data
Statistically, they are extreme value.
Poor-Quality Data
Irrelevant Features
Means too many features with too little data.
Overfitting the Training Data
Underfitting the Training Data
-EOF-
I find it's a bit slow trying to write every part in detail, maybe I was really too meticulous as writing a reading note, next time I'll try to conclude in my own words instead of using lots of words directly from the book.